人工知能が人と同じ視線を獲得した!
「詰め込み教育」ではだめ、「情報量を最大化する自発的な学習」が鍵
| 原著論文 | Neural Netw. 189:107595 (2025) |
|---|---|
| 論文タイトル | Emergence of Human-Like Attention and Distinct Head Clusters in Self-Supervised Vision Transformers: A Comparative Eye-Tracking Study |
| 研究室サイト | ダイナミックブレインネットワーク研究室〈北澤 茂 教授〉 |
概要
大阪大学大学院生命機能研究科ダイナミックブレインネットワーク研究室の北澤茂教授と大阪大学大学院医学系研究科脳生理学研究室の山本拓都さん(博士課程)らは、動画を見るときの人間の視線計測データと人工知能(ViT)の「注意」を比較して、情報量を最大化する自発的な学習(DINO法の学習)をした人工知能が人間と極めてよく似た場所を見るように「育つ」ことを発見しました。一方で、画像識別を行うように「詰め込み」型の教育を受けたViTは、人間とは違うところを見るようになりました。
DINO法の学習をした人工知能は、一切「顔」の概念を教えていないのに、テレビ番組や映画のシーンを見せると、その場の主役を選んでその顔を見るようになりました。さらに、視覚心理学で注意の研究に使われる人工的な画像に対しても、人間とよく似た場所を見ることが明らかになりました。
ViTには、複数の注意の主体(ヘッド)が設定されています。さらに詳しく注意のヘッドを解析したところ、人間とよく似た場所に注意を向けるグループ1、場面に登場する人や物全体に注意を向けるグループ2、さらに背景だけに注意を向けるグループ3、の3群に分かれることが明らかになりました。
伝統的な心理学では、心は世界を注意の対象である「図」とそれ以外の「地」に分離するとされてきました(図地分離)。本研究のDINO法で育てたViTは、図を図の全体(グループ2)と図の中心(グループ1)に分けていました。人間の視線がグループ1と一致したことから、人間もViTのように世界を3群に分けて理解している可能性が示唆されます。
本研究の成果は、人と相性が良い人工知能の開発や、人間にとって自然な教育・学習法の開発・評価に応用されるものと期待されます。
研究の背景
Chat GPT(generative pretrained transformer)にも使われているトランスフォーマーはもともと言語処理のために2017年に考案された人工神経回路です。言語の場合、文章をおおよそ単語に区切って「トークン」と呼ばれるスロットに入力して、情報を処理していきます。また、画像を碁盤目状に細かく分割して得られる細片を「トークン」に入力すると、画像の処理にも威力を発揮します。これがビジョン・トランスフォーマー(Vision Transformer、ViT)です。ViTは、もともと画像の分類(この写真は何か?)に用いられていました。ViTには、クラス・トークンと呼ばれる画像全体の情報を集約するための特殊なトークンが用意されていて、このクラス・トークンが集約した情報を使って最終的な分類判断を下す構造になっています。画像全体からの情報集約に使われるのが、attention head(注意のヘッド)です。クラス・トークンの注意のヘッドは画像全体から重要そうな場所に注意を向けて情報を集約します。 人間の場合、一番大事なところに注意=目(視線)を向けますが、ViTの注意は人間と同じ場所に向いているのか定かではありません。そこで、ViTの注意のマップを描いて、そのピークをViTが「見る」とみなして、人間で計測した視線データと比較することにしました(図1)。
本研究の成果
本研究では、ViTを複数個体を育てて実験に用いました。トランスフォーマーの構造としては、4層、8層、12層の3種類、学習方法としては、100万枚の画像のラベル(分類の正解)を強制的に教え込む教師付き学習法(Supervised Learning、SL法)と、新たな画像から得られる「情報量」を最大化する「自発的」な学習(Distillation with No Label、DINO法)の2種類を採用しました。これら6通りについて、6個体ずつ育てた上で、人間が映画やテレビ番組を見ているときの視線データ(Nakanoら2010、Costela & Woods 2010から使用)と比較しました。
その結果、教師付学習法(SL法)で育てたViTの注意は定型発達の人とは全く異なる一方、自律学習法(DINO法)で育てた8層と12層のViTの注意は定型発達の成人と極めて類似することを発見しました(図2)。つまり、構造が全く同じViTでも、詰め込み学習(SL法)ではヒトの注意には似らず、ヒトに似た注意は、正解を与えない「自発的」な情報量最大化学習(DINO法)によってのみ獲得されることが示されました。
ViTの各層のクラストークンには6個の注意のヘッドが準備されています。つまり、12層のViTには注意の主体が12x6=72個用意されています。その中でヒトに似た注意を示す注意のヘッドは12層ViTの9層と10層と8層ViTの7層と8層に出現していました(図2左下)。そこで、これら4層の注意のヘッド24個を6個体分、計144個集めて注意パターンの距離を使って分類したところ、注意のヘッドは3群に分かれました(図3左、G1、G2、G3)。
これら3群のヘッドの注意を比較したところ、G1はヒトと同様に顔に注意を向け、G2はヒトの体全体に注意を向け、G3は背景に注意を向けることが明らかになりました(図3右)。様々なシーンに関して検討した結果、G1は図の中心、G2は図の全体、G3は地に注意を向ける、と結論しました。
さらに、心理学の分野で注意の研究に用いられる人工的な画像をViTに見せたところ、人間と同様に色、大きさ、形、傾きの仲間外れや、ハッチングの切替領域に注意を向けました(図4)。
強調したいのは、人の「顔」というラベルや、図4のような人工的な画像をDINO法の学習では一切使っていないことです。ViTはあくまでも、様々な画像から得られる「情報量」を最大化するように学習を行うのですが、人間にとてもよく似た注意が創発しました。
人間が誕生し成長する過程では、ラベルの付いた画像で正解のラベルを学習するわけではありません。何もわからないまま、世界から何かの情報を得よう、あるいは何かの意味を見出そうとして自発的に学習しています。
私たちは、DINO法に基づくViTの学習過程が、人間の生後の脳、とりわけ視覚系、で図と地の分離が生じる過程の優れたモデルになると考えています。 さらに、本研究では、注意の基本は図地の2群だけではなく、図の中心であるG1を加えた3群であるという新たな仮説を提案します。
今後は、G1、G2、G3が本当に脳の中にあるのか、またあるとすればどこにあるのかについて研究を進めます。
研究成果のポイント
- 情報量を最大化する自発的な学習を行ったビジョン・トランスフォーマー(ViT)と呼ばれる人工知能が、人間と極めてよく似た場所を見るように「育つ」ことを発見。
- 人間の脳がどのように視覚情報を処理し、どこに注意を向けるのかはまだ完全に理解されていないため、人間のような注意機構をAIで再現することは困難だった。
- ViTは、場面を「人や物の中心」、「人や物の全体」、「場面の背景」の3群に分解して注意を向けていることから、人間もViTのように世界を3群に分けて理解している可能性が示唆された。
- 人と相性が良い人工知能の開発や、人間にとって自然な教育・学習法の開発・評価への応用が期待
本研究成果が社会に与える影響(本研究成果の意義)
人と相性が良い人工知能の視覚部分の開発や、人間にとって自然な教育・学習法の開発・評価への応用が期待されます。
研究者のコメント
テレビや映画を見るとき、我々の視線は驚くほど一致した動きを示します。人工知能はどうなのでしょうか。驚いたことに、同じ構造の人工知能でも、「育て方」次第で人に似ることもあれば、似ないこともある、ことがわかりました。のびのびと学習した個体だけが人間に似た視線の動きを獲得したのです。人間の育て方にも大いに示唆を与える結果だと思います。(北澤茂)
特記事項
本研究成果は、2025年5月21日に国際科学誌電子版「Neural Networks」に掲載されました。
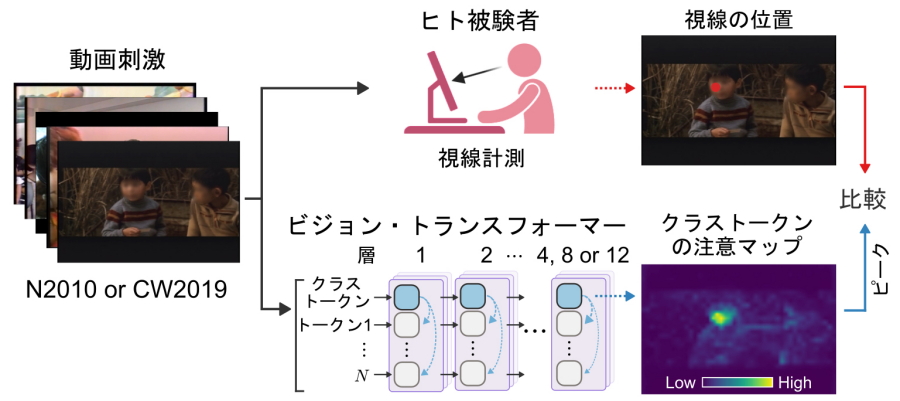
図1.ViTの注意の時系列とヒトの視線時系列を比較した
ViTとして4層、8層、12層の3種類を準備した。それぞれについて、教師付学習法(SL法)で学習させた6個体と、ラベルなしで情報量を最大化する自律学習法(Distillation with No Label、DINO法)で学習させた6個体、計36個体を準備して人間のデータ(Nakanoら2010、Costela & Woods, 2019)と比較した。
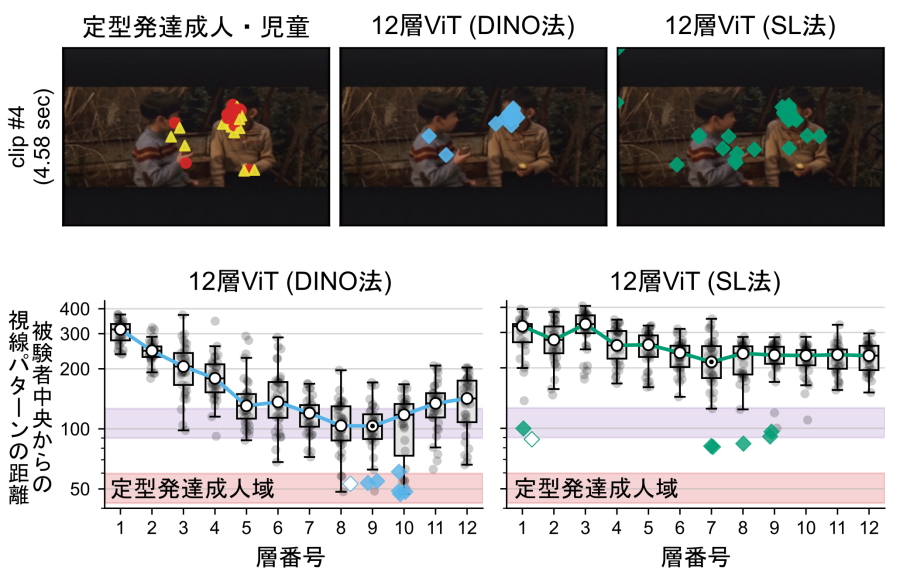
図2.自発的に学習したViTの注意はヒトとよく似る
上:二人の子どもの会話シーンで人間の視線はほぼ右の子どもの顔に集中する(左)。DINO法の個体は右の子どもの顔を見る(中)。一方、SL法のViTの視線はばらつく(右)。下:層ごとに注意のヘッドが人間の視線からどれくらい離れているかを定量化した。DINO法ViTでは9層と10層に人間と同じ注意を示すヘッドが出現していた。

図3.自発的に学習したViTの注意のヘッドは3群に分かれた
DINO法ViT12個体で、ヒトに似た注意が出現した層のヘッド144個を多数の画像に対する注意の距離で多次元尺度法を適用して分類したところ、3群(G1、G2、G3) に分かれた。G1は図の中心(人なら顔)、G2は図の全体(人なら体全体)、G3は地(背景)に注意を向けていた。

図4.人工的な刺激に対しても人間に似た注意を示す
人間は色、大きさ、形、傾きの仲間外れや、ハッチングの切替領域に敏感。人工画像を使った学習は一切していないのにDINO法ViTのG1ヘッドも同様。
用語解説
- ビジョン・トランスフォーマー(Vision Transformer、ViT)
2020年にDosovitsikiyらがトランスフォーマーのトークンに、画像の細片を入力して、画像の分類に転用したのがビジョン・トランスフォーマーの始まりである。オリジナルのトランスフォーマーにはないクラス・トークンと呼ばれるトークンが追加されていて、このクラス・トークンが画像全体の情報に注意を使ってアクセスして、重みづけして情報を統合する。2020年に発表されたViTでは、100万枚の画像を使って、あらかじめ各画像に付与された「ラベル」を出力するように、教師付き学習法(Supervised learning、SL法)で訓練が行われた。 - DINO法(Distillation with No Label method、ラベルなし蒸留法)
2021年にCaronらがViTの学習に導入した学習法。生徒と先生役を果たす2つの同じ構造のViTを準備して、生徒が先生を模倣しつつ、先生は生徒の履歴を複製コピーするという相互依存的な関係を持ちながら、画像から得られる情報量を最大化する学習を実現している。目が動いて網膜像が揺れても世界の情報が変わらないことを要求しつつ、世界から得られる情報量を最大化するという実用的な学習法である。 - 図地分離
図地分離とは、視覚情報処理において、「注目すべき対象(図)とその背景(地)」とを区別して知覚する脳の基本的な働きを指す。これはゲシュタルト心理学の中核的概念であり、われわれの視覚系が複雑な環境から意味ある情報を抽出するうえで不可欠とされてきた。 - トランスフォーマー(Transformer)
2017年にVaswaniらが考案した言語翻訳用の人工神経回路。英語を単語(トークン)に分解して入力すると、正しいドイツ語が出力されるように1億語のデータで訓練した。それまでの人工神経回路と異なり、各層に横方向の情報のやり取りを行うアテンション(注意)のメカニズムを導入した。このアテンションを導入することで、ある単語の意味を捉えるのに周辺の単語の情報を文脈として使うことが可能となり、複数の意味を持つ単語に、適切な意味を付与することが可能となった。トランスフォーマーは横方向のアテンションのおかげで、大変優れた言語処理能力を獲得したため、Chat GPTをはじめとするその後の大規模言語モデルは、すべてトランスフォーマーである。大きく違うのはサイズだけ。最初のトランスフォーマーは6層だったのに、2023年に発表されたChat GPT4は巨大化して数百層となり、訓練には1兆語のデータが用いられたと推定されている。
| 原著論文 | Neural Netw. 189:107595 (2025) |
|---|---|
| 論文タイトル | Emergence of Human-Like Attention and Distinct Head Clusters in Self-Supervised Vision Transformers: A Comparative Eye-Tracking Study |
| 著者 | Takuto Yamamoto (1), Hirosato Akahoshi (2), Shigeru Kitazawa (1, 2, 3)
|
| PubMed | 40424761 |